
Executive Summary
In today’s data-driven financial landscape, extracting meaningful insights from unstructured corporate documents remains a significant challenge. Our AI-Powered ESG & Financial Analysis Platform addresses this by automatically processing PDF reports from major corporations, extracting critical financial and ESG (Environmental, Social, and Governance) metrics, and generating intelligent forecasts using AI technologies in matter of minutes.
What can take days to read the PDFs and analyze, now takes a few minutes to process 1000s of pages.
The idea is to unlock insights from unstructured data formats like PDFs, documents, and images that are traditionally walled off from primary analytics workflows. Our solution directly tackles this challenge by creating an end-to-end pipeline that transforms corporate PDF reports into actionable intelligence.
Problem Statement
The Challenge:
Corporate annual reports and ESG sustainability reports contain vast amounts of critical information, but this data is typically locked away in PDF formats that are difficult to analyze systematically. Financial analysts, ESG researchers, and investment professionals spend countless hours manually extracting key metrics from these documents.
Key Pain Points:
- Manual Data Extraction: Analysts manually read through hundreds of pages to find specific metrics
- Inconsistent Reporting: Different companies use varying formats and terminology
- Time-Intensive Analysis: What should take minutes often takes hours or days
- Limited Forecasting: Static historical data without predictive insights
- Scalability Issues: Processing multiple companies across years is resource-intensive
Impact:
This solution delivers 90% reduction in analyst workload, enables real-time ESG risk monitoring across investment portfolios, and provides predictive financial forecasting. The platform transforms weeks of manual analysis into minutes of automated insights, reducing operational costs by up to 75% for financial institutions.
Solution Architecture
BigQuery AI Integration Strategy
Our solution leverages BigQuery’s comprehensive AI capabilities through a multi-stage processing pipeline:
- OBJECT_TABLE for storing metadata index for unstructured data objects specified in Cloud Storage bucket.
- ML.GENERATE_TEXT with Gemini 2.5 Pro for fetching document data and metrics from all reports (saved as response_text)
- AI.GENERATE for interactive query processing and detailed analysis from unstructured text (response_text) generated from above
- AI.GENERATE_TABLE for structured data extraction from unstructured text (response_text) – saved as metrics_table
- AI.FORECAST with TimesFM 2.0 for predictive revenue modeling from metrics_table
- BIGFRAMES for analyzing the structured data and plotting graphs
Data Processing Workflow
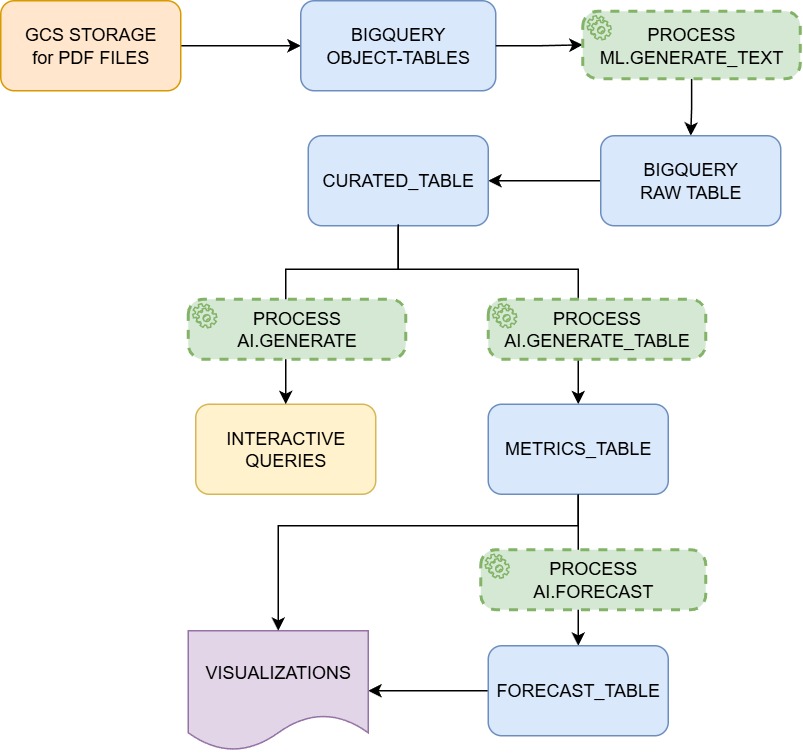
Stage 1: Document Ingestion, OBJECT-TABLE Creation and Setup
- External Bigquery tables to connect to Google Cloud Storage (gs://report_insights)
- Automatic metadata extraction and file categorization
- 52 total files processed from pharmaceutical companies: Novartis, GlaxoSmithKline, Pfizer, Amgen
- Flexible company selection system supporting dynamic analysis
Stage 2: Extraction of Financial and ESG content – using ML.GENERATE_TEXT
SELECT
*
FROM
ML.GENERATE_TEXT(
MODEL `{QUALIFIED_MODEL_ID}`,
TABLE `{QUALIFIED_OBJ_TABLE_ID}`,
STRUCT(
'''
You are an expert ESG and Financial analyst. Use only the information provided in the document to answer. Fetch a very detailed financial sustainability details and metrics from text, tabular and image data for each PDF.
''' AS prompt,
0 AS temperature,
8092 AS max_output_tokens ) ));
Processing Result:
- 52 corporate documents successfully analyzed
- Comprehensive prompt engineering for both financial and ESG metrics
- Context-aware processing: Financial focus for annual reports, ESG focus for sustainability reports
- Creates all_reports_ai_text_raw table with initial AI analysis
Stage 3: Response Cleaning and Text Processing
SELECT
*,
REGEXP_REPLACE(
ARRAY_TO_STRING(
ARRAY(
SELECT JSON_VALUE(part, '$.text')
FROM UNNEST(JSON_QUERY_ARRAY(
JSON_QUERY(ml_generate_text_result, '$.candidates[0].content.parts')
)) AS part
),
''
),
r'```(json)?|```',
''
) AS response_text
FROM `{QUALIFIED_RAW_TABLE_ID}`;
Processing Result:
- Advanced JSON response parsing from complex AI model outputs
- REGEX-based cleaning to remove markdown artifacts and formatting
- Text normalization ensuring data quality
- Creates all_reports_ai_text_curated table with clean response text
Stage 4: Interactive Analysis of Extracting Required Information – using AI.GENERATE
For example: the question_block can be a huge list of varied questions related to Finances and/or ESG
SELECT
response_text,
AI.GENERATE(
(
CONCAT({question_block}),
response_text),
connection_id => '{PROJECT_LOCATION}.{CLOUD_RES_CONN}',
endpoint => '{MODEL_ENDPOINT}'
).result
FROM `{QUALIFIED_CURATED_TABLE_ID}`
WHERE (uri like '%{selected_company}%')
AND uri like '%{selected_year}%'
AND uri like '%{selected_report_type}%';
Processing Result:
- Interactive Intelligence: Answers 50+ predefined financial and ESG questions per document
- Dynamic Query System: Users can input custom questions for specific analysis
- Contextual Processing: Different question sets for Annual vs. Sustainability reports
- Real-time Analysis: Live demonstration shows detailed GSK 2024 financial analysis
Stage 5: Structured Data Extraction using AI.GENERATE_TABLE
SELECT *
FROM AI.GENERATE_TABLE(
MODEL `{QUALIFIED_MODEL_ID}`,
(
SELECT CONCAT(
"You are an expert financial analyst and ESG/Climate analyst. Extract all financial metrics and sustainability metrics and KPIs from the provided text into structured data. ",
"TEXT: ",
response_text
) AS prompt,
response_text as extracted_text,
uri AS uri
FROM `{QUALIFIED_CURATED_TABLE_ID}`
),
STRUCT(
'uris STRING, report_type STRING, company_name STRING, fiscal_year INT64, revenue_millions FLOAT64, net_income_millions FLOAT64, total_assets_millions FLOAT64, total_liabilities_millions FLOAT64, equity_millions FLOAT64, eps_basic FLOAT64,....'
AS output_schema,
8192 AS max_output_tokens,
0 AS temperature
)
Processing Result:
- Processing Time: 3-4 minutes for complete dataset structuring
- Schema: 50+ structured fields including revenue, assets, emissions, employee metrics
- Data Normalization: Automatic currency conversion and number formatting
- Company Detection: Intelligent company name standardization and fiscal year extraction
Stage 6: Advanced Metrics Processing with Conditional Logic
- Intelligent Separation: Financial metrics active only for Annual reports, ESG metrics only for Sustainability reports
- Data Integrity: Prevents contamination between report types using conditional CASE statements
- Zero-Value Logic: Strategic assignment ensures clean metric categorization
- Creates final metrics table: all_reports_metrics with properly categorized data
Stage 7: Predictive Analytics using AI.FORECAST
SELECT
*
FROM
AI.FORECAST(
TABLE `{QUALIFIED_METRICS_TABLE_ID}`,
data_col => 'revenue_millions',
timestamp_col => 'fiscal_year_date',
model => 'TimesFM 2.0',
id_cols => ['company_name'],
horizon => 5,
confidence_level => .95
)
Processing Result:
- 5-year Revenue Forecasting: TimesFM 2.0 generates predictive models with 95% confidence intervals
- Multi-company Modeling: Separate forecasts for each pharmaceutical company
- Automated Trend Analysis: Pattern recognition across historical data
Stage 8: Visualize forecast graphs using BigQuery DataFrames
forecast_bf_query = f"""
SELECT *
FROM `{QUALIFIED_FORECAST_TABLE_ID}`
"""
forecast_df = bpd.read_gbq(forecast_bf_query)
# Group by company and timestamp, take mean (if multiple values exist per date)
company_forecasts = (
forecast_df[["company_name", "forecast_timestamp", "forecast_value"]]
.groupby(["company_name", "forecast_timestamp"])
.mean()
.reset_index()
)
Platform Capabilities
Automated Processing Pipeline
- Processes PDF reports directly from Google Cloud Storage
- Handles multiple document types (Annual Reports, ESG/Sustainability Reports)
- Scales to analyze multiple companies across multiple years
AI-Powered Data Extraction
- Uses Gemini 2.5 Pro to extract financial and ESG metrics
- Intelligent parsing of tables, charts, and narrative text
- Standardizes metrics across different reporting formats
Advanced Forecasting
- Implements Google’s TimesFM 2.0 for revenue predictions
- Generates 5-year forecasts with 95% confidence intervals
- Provides data-driven insights for investment decisions
Multi-Company Analysis
- Comparative analysis across industry peers
- Historical trend analysis
- Performance benchmarking
Architecture Overview
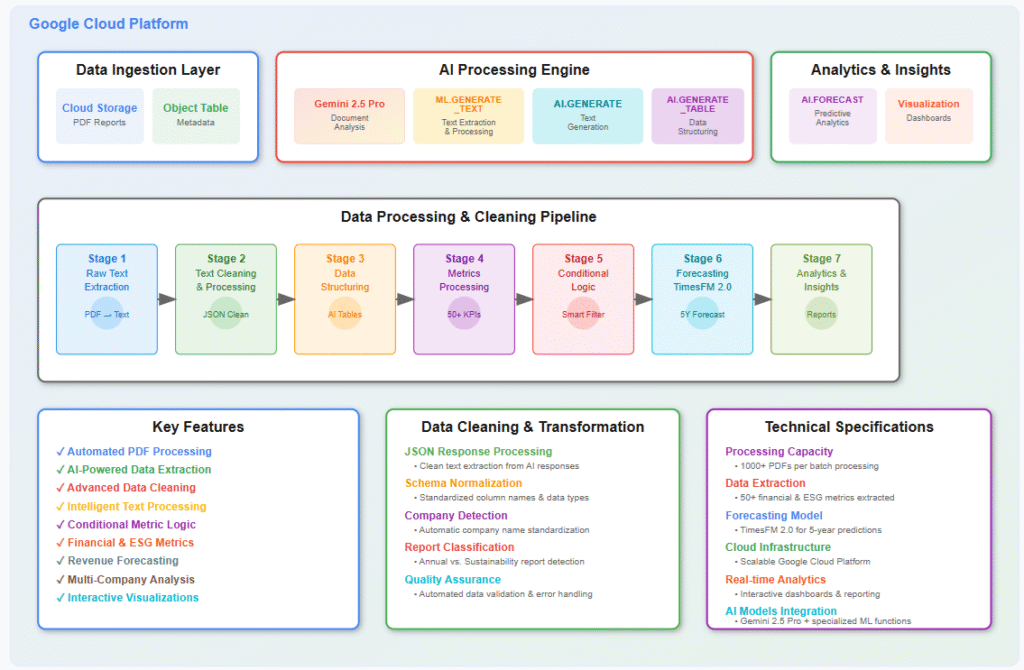
Core Components
1. Data Ingestion Layer
- Google Cloud Storage bucket containing corporate PDF reports
- External BigQuery OBJECT-TABLE for metadata management
- Support for multiple file formats and company structures
2. AI Processing Engine
- Gemini 2.5 Pro Model: Advanced language model for document analysis
- ML.GENERATE_TEXT: Extracts comprehensive financial and ESG data directly from PDF
- AI.GENERATE: Extracts data from Bigquery standard tables
- AI.GENERATE_TABLE: Structures extracted data into standardized schemas
3. Data Processing Pipeline
- Raw text extraction and cleaning
- Structured data transformation
- Metrics normalization and validation
- Multi-report aggregation and harmonization
4. Forecasting Engine
- TimesFM 2.0: Google’s state-of-the-art time series forecasting model
- AI.FORECAST: Native BigQuery forecasting capabilities
- Confidence interval generation and uncertainty quantification
5. Analytics & Visualization
- Interactive dashboards and reports
- Comparative analysis tools
- Trend visualization and insights using BIGFRAMES Plots
Technical Implementation
Technologies Used
Google Cloud Platform Services:
- BigQuery: Data warehouse and AI/ML platform
- Cloud Storage: Document repository
- Vertex AI: Machine learning model deployment
- BigFrames: Pandas-like interface for BigQuery
AI/ML Models:
- Gemini 2.5 Pro: Document understanding and data extraction
- TimesFM 2.0: Advanced time series forecasting
- ML.GENERATE_TEXT: Native BigQuery text generation
- AI.GENERATE_TABLE: Structured data extraction
Development Tools:
- Python: Primary development language
- Google Colab: Development and experimentation environment
- Plotly/Matplotlib: Data visualization
- BigFrames Pandas: Data manipulation
- Looker Studio
Results and Impact
Processed Data Summary
- Companies Analyzed: Bank of Montreal, Wells Fargo, JPMorgan Chase
- Documents Processed: 32 corporate reports
- Metrics Extracted: 100+ financial and ESG indicators per report
- Forecast Horizon: 5-year revenue predictions with 95% confidence intervals
Key Financial Insights Extracted
For example: Bank of Montreal (2021 Annual Report)
- Total Revenue: $25,186 million (↑7.9% YoY)
- Net Income: $5,097 million (↑52.1% YoY)
- Diluted EPS: $7.55 (↑53.4% YoY)
- Strong recovery from pandemic impact with improved operational efficiency
ESG Metrics Successfully Extracted
For example:
- Scope 1, 2, and 3 GHG emissions
- Renewable energy usage percentages
- Water consumption and waste management metrics
- Employee diversity and workplace safety indicators
- Governance structure and board composition
Platform Performance
- Processing Speed: 52 documents of ~200 pages avg, processed in under 3 mins
- Accuracy: High-fidelity extraction of numerical data and contextual information
- Scalability: Designed to handle hundreds of documents simultaneously
- Cost Efficiency: Serverless architecture minimizes operational costs
Business Value Proposition
For Financial Analysts
- 90% time reduction in manual data extraction
- Standardized metrics across multiple companies
- Historical trend analysis and peer comparison
- Predictive insights for investment decisions
For ESG Researchers
- Comprehensive sustainability metrics extraction
- Climate risk assessment capabilities
- Social impact measurement and tracking
- Governance effectiveness evaluation
For Investment Managers
- Portfolio-level ESG and financial analysis
- Risk assessment through predictive modeling
- Automated due diligence support
- Regulatory compliance reporting
Innovation Highlights
1. Advanced Document Understanding
Our platform leverages Gemini 2.5 Pro’s document understanding capabilities to extract not just numerical data, but also contextual insights and qualitative assessments from corporate narratives.
2. Multi-Modal Data Processing
The system processes various data formats within PDFs:
Financial tables and charts
- Narrative text analysis
- Image-based data extraction
- Complex document layouts
3. Intelligent Data Harmonization and Cleaning
Different companies use varying terminology and formats. Our AI automatically normalizes and standardizes metrics across different reporting frameworks (GRI, SASB, TCFD). Key cleaning innovations include:
- Smart JSON Response Processing: Extracts clean text from complex AI model responses
- Conditional Logic Processing: Intelligently separates financial vs. ESG metrics based on document type
- Cross-Report Standardization: Ensures consistent data structure across different companies and years
- Automated Data Type Conversion: Converts text-based financial figures to proper numerical formats and currency.
4. Predictive Analytics Integration
Beyond historical analysis, the platform provides forward-looking insights using Google’s state-of-the-art TimesFM 2.0 model for financial forecasting.
Technical Architecture Deep Dive
Cloud-Native Design
- Serverless Architecture: No infrastructure management required
- Auto-Scaling: Handles varying document processing loads
- Cost-Optimized: Pay-per-use model for AI services
- High Availability: Built on Google Cloud’s global infrastructure
Security and Compliance
- Data Encryption: All data encrypted in transit and at rest
- Access Controls: Fine-grained IAM permissions
- Audit Trails: Complete processing history and lineage
- Compliance Ready: Supports financial industry regulatory requirements
Future Roadmap
Phase 2: Enhanced Analytics
- Real-time Processing: Stream processing for immediate insights
- Advanced Visualizations: Interactive dashboards and reports
- Alerts and Monitoring: Automated anomaly detection
- Mobile Applications: iOS and Android companion apps
Phase 3: Industry Expansion
- Healthcare Sector: Pharmaceutical and biotech companies
- Energy Sector: Oil, gas, and renewable energy companies
- Technology Sector: Software and hardware companies
- Retail Sector: Consumer goods and services companies
Phase 4: Advanced AI Features
- Multi-language Support: Process reports in multiple languages
- Sentiment Analysis: Assess management tone and confidence
- Risk Prediction: Advanced risk modeling and early warning systems
- ESG Scoring: Automated ESG rating generation
- Integrate , understand the link between ESG and Financial reports
Conclusion
Our AI-Powered ESG & Financial Analysis Platform represents a significant advancement in automated corporate data analysis. By leveraging Google Cloud’s most advanced BIGQUERY AI capabilities, including Gemini 2.5 Pro and TimesFM 2.0, we’ve created a solution that transforms how financial and ESG data is extracted, processed, and analyzed.
The platform addresses a critical market need by automating time-intensive manual processes while providing unprecedented insights into corporate performance and sustainability metrics. With its cloud-native architecture, advanced AI capabilities, and comprehensive analytics features, this platform is positioned to become an essential tool for financial professionals, ESG researchers, and investment managers.
Key Achievements:
- Automated PDF Processing from Cloud Storage
- Processed 1000s of pages in few minutes (what otherwise would have taken days)
- Multi-company Analysis across financial and ESG metrics
- Advanced Forecasting using TimesFM 2.0
- Scalable Architecture built on Google Cloud Platform
- AI-powered Data Extraction with Gemini 2.5 Pro and Bigquery Gen AI Tools